AI Support Agent That Deflects 60% of Tickets
A support copilot trained on product docs that resolves most queries instantly and hands off the rest.
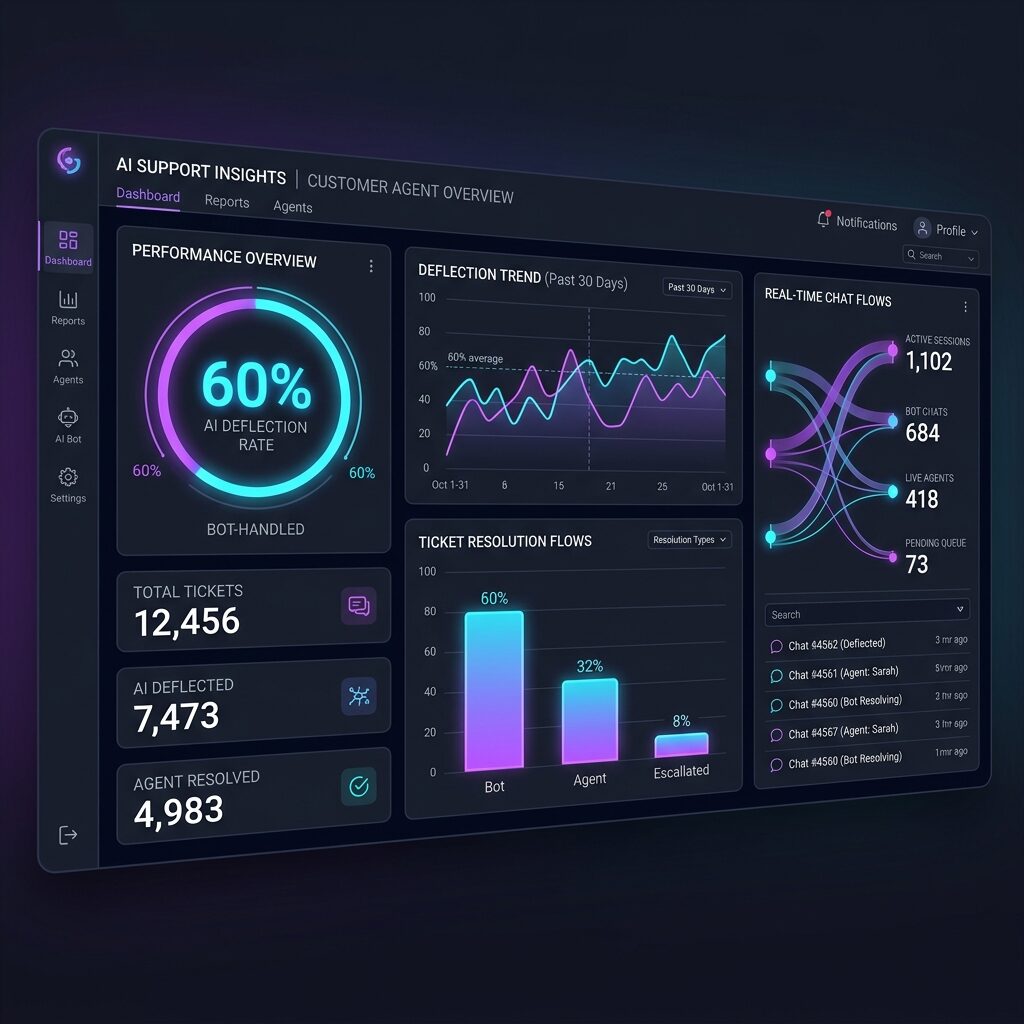
HelpStack is a fast-growing B2B SaaS product, and its success had quietly turned its support function into a bottleneck. Monthly ticket volume had roughly tripled over the prior year while the support team grew only modestly, leaving a backlog that pushed median first-response times past four hours and well beyond a full day during peak periods. The team was spending the bulk of its hours answering the same recurring "how do I" questions — questions already documented in a thorough knowledge base that customers either could not find or would not read.
The cost was showing up in the metrics that mattered. CSAT was sliding, churn conversations increasingly cited slow support, and hiring more agents was both expensive and slow to onboard given the product's depth. Leadership wanted to deflect the repetitive volume without doing what most automated support tools do: frustrate customers with confidently wrong, hallucinated answers that erode trust faster than no answer at all.
So the bar was specific. Any AI layer had to answer only from HelpStack's real, current documentation, admit when it did not know, and hand off cleanly to a human with full context — never trap a customer in a dead-end bot loop.
We built a retrieval-augmented (RAG) support agent grounded entirely in HelpStack's own knowledge base, help articles, and changelog, so every answer is sourced from material the company actually maintains rather than the model's general training data.
The ingestion pipeline, written in Python, chunks and embeds HelpStack's content into a Pinecone vector index, and re-syncs automatically whenever docs change so the agent never serves stale guidance. At query time, the most relevant passages are retrieved and passed to an OpenAI model with strict instructions to answer only from the supplied context and to cite the source articles it used.
The pieces that made it trustworthy in production:
- Confidence-gated responses: when retrieval scores are weak or the model is unsure, the agent declines to guess and routes the conversation to a human instead of fabricating an answer.
- Context-rich escalation: handoffs carry the full conversation, the customer's account details, and the agent's best understanding of the issue, so human agents pick up without making the customer repeat themselves.
- A Laravel control panel where the support team reviews transcripts, flags bad answers, and curates the knowledge base — creating a feedback loop that steadily improves deflection over time.
- Full analytics on deflection rate, escalation reasons, and answer quality so HelpStack can see exactly what the agent handles and where the docs have gaps.
We rolled it out behind the existing support widget, starting with a subset of topics and expanding coverage as quality was proven. Within the first quarter the agent was confidently resolving 60% of incoming tickets end to end, freeing the human team to focus on the complex, high-value cases.
Technology used
Related case studies
 Fintech
Fintech
Scaling a Fintech Lending Platform
We rebuilt a monolithic loan platform into a modular system that cut approval times from days to minutes.
 E-commerce
E-commerce
A Delivery App That Hit 500k Downloads
A cross-platform delivery app with offline support and live tracking that scaled to half a million users.
From 200 to 40,000 Organic Visitors a Month
A technical SEO overhaul and content engine that grew organic traffic 200x in a year.
Want results like these?
Tell us about your goals and we'll map out how we'd get you there — no commitment required.